


Współczesny Internet jest zlepkiem licznych rozwiązań technologicznych. Gdy te rozwiązania są wykorzystywane zgodnie z ich oryginalnym przeznaczeniem, potrafią dać użytkownikom nowy rodzaj swobód i możliwości. Niestety właściwie każdy aspekt Internetu jest także wykorzystywany w celu śledzenia jego użytkowników. W niniejszym artykule i odcinku omówimy metody zbierania danych utożsamiających użytkowników internetu oraz sposoby ich automatycznej transmisji do podmiotów trzecich.

(autor ilustracji: Jan Kryciński)
Odcinek #20
Ten sam temat poruszamy w najnowszym odcinku podcastu, którego możecie posłuchać tutaj:
Jakie informacje udostępnia stronom przeglądarka internetowa?
Dane osobowe to nie tylko np. nasze imię i nazwisko czy PESEL. To wszelkie dane, których można użyć do jednoznacznego określenia naszej tożsamości. Firm zajmujących się śledzeniem użytkowników nie obchodzi, jak oni się nazywają, ale to, co są skłonni kupić i jak tę skłonność wykorzystać. W tym celu potrzebują „tylko” wiedzieć, że np. osoba która teraz wchodzi na stronę z wiadomościami to ta sama osoba, która wczoraj przeglądała oferty sprzedaży konkretnego modelu smartfona na Allegro. Mając takie informacje mogą wyświetlić reklamy tego modelu smartfona, lub modelu konkurencji - zależnie od tego, który reklamodawca zapłaci więcej.
W tym celu strony tworzą identyfikator użytkownika, który następnie za pomocą któryś z opisanych w późniejszej części niniejszego artykułu jest wysyłany do właścicieli stron przy każdych odwiedzinach. Identyfikatory mogą być tworzone na różne sposoby:
1. Identyfikatory losowe
Jest to najprostszy sposób na generowanie identyfikatora. Przy pierwszych odwiedzinach strona generuje ciąg znaków (wyglądający np. tak: 27b22ec2-c68b-4515-b30b-fdb29fdf35ff). Przy następnych odwiedzinach zapytanie wysłane do serwera jest już opatrzone tym identyfikatorem, więc właściciel strony może budować unikalną historię przeglądania w danej witrynie.
Z punktu widzenia skryptów śledzących to rozwiązanie ma tę wadę, że gdy użytkownik w jakiś sposób usunie ten identyfikator ze swojego komputera/przeglądarki lub otworzy stronę w oknie „incognito” lub w innej niż zwykle przeglądarce, to jest tworzony nowy losowy identyfikator, który nie jest powiązany z tym poprzednio wygenerowanym, utrudniając gromadzenie pełnej historii przeglądania na danej stronie.
Na szczęście dla podsłuchowego kapitalizmu, jest sposób na tworzenie identyfikatora, który sam się odrodzi nawet po jego usunięciu:
2. Browser fingerprinting
W odróżnieniu od losowych identyfikatorów, browser fingerprinting polega na zebraniu możliwie dużej ilości informacji o przeglądarce i systemie użytkownika i wygenerowaniu identyfikatora na ich podstawie. Taki identyfikator może nadal wyglądać na losowy (np. 89ae55501722242f5663acb76d49f7cd), pomimo, że nie jest generowany losowo. Efekt taki jest osiągany za pomocą funkcji skrótu.
W dużym uproszczeniu funkcje skrótu w informatyce pozwalają na przetworzenie danych o dowolnej objętości (np. wszystkie dane o systemie operacyjnym, jakie udostępnia stronie przeglądarka) na ciąg znaków o stałej długości. Działają w taki sposób, że zawsze generują taki sam ciąg znaków dla tych samych danych, a nawet drobna zmiana w danych powoduje, że generowany ciąg znaków jest zupełnie inny. Dzięki temu użytkownicy o różnych konfiguracjach sprzętu i systemu operacyjnego będą mieli różne identyfikatory, a dany jeden komputer będzie generował takie samo ID, dopóki jego konfiguracja się nie zmieni.

Taki identyfikator jest nazywany „odciskiem palca przeglądarki” (ang. browser fingerprint).
Dane używane do fingerprintingu
Dokładność fingerprintu jest tym większa, im więcej danych zostanie użytych do jego generowania. Na szczęście dla skryptów śledzących i reklamodawców, przeglądarki udostępniają stronom pokaźną ilość danych o naszych urządzeniach, bez pytania nas o zgodę.
Strona BrowserLeaks zwięźle ilustruje ilość tych informacji i dzieli je na następujące kategorie:
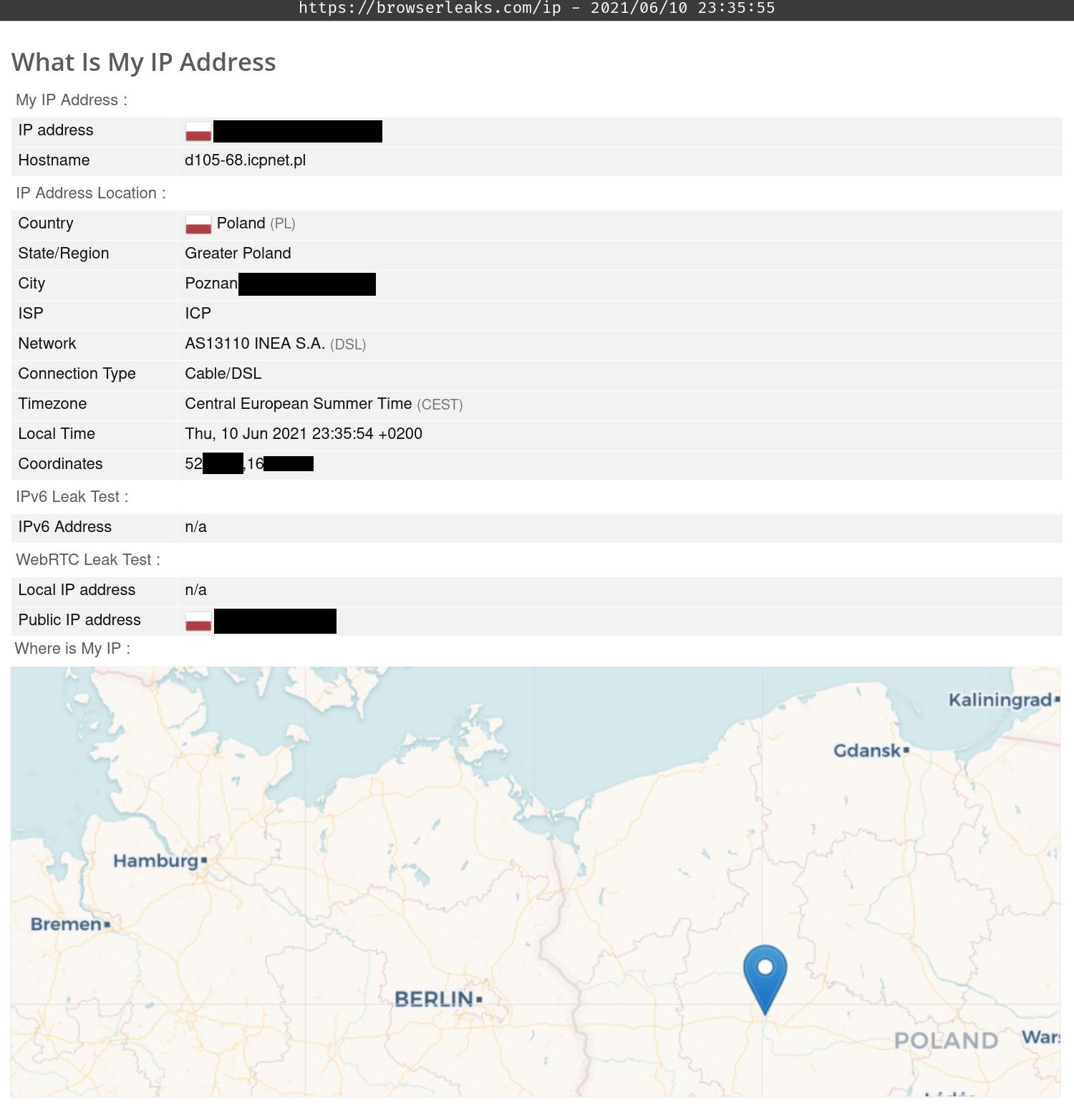
Adres IP
Nie da rady korzystać z Internetu bez ujawniania swojego IP (lub adresu IP VPN-a, z którego korzystamy). Za pomocą adresu IP można określić z grubsza naszą lokalizację (czasem nawet z dokładnością co do miejscowości / dzielnicy) oraz dostawcę łącza internetowego, z którego korzystamy. Dodatkowo przydatne do fingerprintingu mogą być adresy serwerów DNS, z którymi się łączymy.
Za pomocą tego linku można podejrzeć rodzaj i treść danych dotyczących naszego adresu IP, które udostępniamy każdej stronie internetowej: https://browserleaks.com/ip
JavaScript API
„Nowoczesne” strony internetowe to de facto aplikacje, które nasza przeglądarka automatycznie pobiera i uruchamia na naszym komputerze. Udostępniane stronom przez przeglądarkę funkcjonalności (API) pozwalają odczytywać informację m.in. o:
- rozdzielczości ekranu;
- języku ustawionym w systemie;
- systemie operacyjnym;
- ilości rdzeni procesora;
- niektórych cechach naszej karty dźwiękowej.
Za pomocą tego linku można podejrzeć rodzaj i treść danych dotyczących JavaScriptowych API, które udostępniamy każdej stronie internetowej: https://browserleaks.com/javascript
WebRTC
Dzięki technologii WebRTC użytkownicy mogą prowadzić rozmowy audio/video z poziomu przeglądarki, bez potrzeby instalacji osobnych aplikacji, a reklamodawcy mogą automatycznie pozyskiwać informacje o ilości i rodzajach mikrofonów i kamerek podłączonych do naszego komputera.
Link do testu ilości informacji z WebRTC.
Canvas
Canvas to funkcja HTML5 pozwalająca aplikacjom, jakimi są strony internetowe, na tworzenie grafik dynamicznie, po stronie naszej przeglądarki, piksel po pikselu. Dzięki temu użytkownicy mogą cieszyć się aplikacjami, które potrafią generować i obrabiać grafiki z poziomu przeglądarki (aby je potem np. pobrać na dysk).
Jak skrypty śledzące z tego korzystają? Otóż Canvas ma funkcję np. do nakładania tekstu na obrazek. Różne systemy operacyjne i przeglądarki generują tekst na delikatnie różne sposoby (różnice mogą dotyczyć chociażby sposobu wygładzania fontów). Na pierwszy rzut oka mogą to być niewidoczne różnice, ale nawet piksel różnicy jest dla funkcji skrótu istotną informacją.
Strony korzystające z Canvas Fingeprinting generują mały obrazek, na którym rysują kilka kształtów i nakładają jakiś tekst (czasem z emoji - w końcu różne systemy mają różnie wyglądające emoji...). Sam obrazek chowają przed użytkownikiem, patrzą tylko na jego treść i dokładają do fingerprinta.
Obrazek ten może wyglądać chociażby tak:

Wykonaliśmy test Canvas Fingerprintingu na naszych przeglądarkach za pomocą BrowserLeaks. Dzięki temu dowiedzieliśmy się, że spośród prawie 800 tysięcy osób, które wykonały ten test, tylko u 62 osób ten obrazek wygenerował się dokładnie tak samo, jak na komputerze Kuby. W przypadku komputera Arkadiusza było to tylko 7 osób... Korzystanie z Linuxa i Firefoxa zapewne sprawia, że jesteśmy bardziej unikalni, co ułatwia śledzenie nas...
WebGL
WebGL można opisać jako Canvas na sterydach - pozwala wykorzystywać kartę graficzną naszego urządzenia do generowania trójwymiarowych obrazów i interaktywnych animacji. Z większą mocą wiąże się jednak większa ilość udostępnianych informacji. Za sprawą wspierania WebGL przeglądarka udostępnia stronom bez naszej zgody m.in. informacje o producencie i modelu naszej karty graficznej.
Fonty
Przeglądarka udostępnia stronom listę zainstalowanych na naszym systemie fontów. Pozwala to ze szczególną precyzją identyfikować osoby, które instalują dodatkowe fonty - np. grafików. Zainstalowane fonty różnią się też pomiędzy różnymi systemami operacyjnymi.
Niektóre aplikacje desktopowe (np. TeamViewer) instalują w systemie unikalne fonty, które następnie mogą być użyte do wykrywania na dowolnej stronie internetowej, czy użytkownik zainstalował daną aplikację, czy nie.
Supercookie
Supercookie jest z podobne do LocalStorage w tym, że wykorzystywane są dane przechowane w przeglądarce użytkownika. Zamiast jednak używać generalnego mechanizmu zapisu danych, używa tzw. favicon cache, czyli schowka, w którym przeglądarka zapisuje ikonki wyświetlane przy tytułach kart. Normalnie nie ma w nim nic złego, i nie jest on dostępny dla witryn, które odwiedzamy, ale powstało badanie, z którego wynika, że można użyć pomiaru opóźnień w ładowaniu ikonek, żeby stwierdzić, które z nich znajdują się w cache’u. To daje śledzącemu informację o tym, które strony dany użytkownik już odwiedził, co z kolei pozwala stworzyć unikalny fingerprint jego przeglądarki.
Takie strony, których ikonki sciąga nasza przeglądarka, technicznie mogą być po prostu przekierowaniami kontrolowanymi przez właściciela strony, dostawcę reklam czy innego brokera danych. W tym właśnie leży, według autorów badania, największe zagrożenie - wystarczą 32 przekierowania, by jednoznacznie oznaczyć każdą osobę z dostępem do Internetu. Istnieje demo na Microsoft Github, które pozwala sprawdzić, czy nasza przeglądarka jest podatna na taką metodę śledzenia. Firefox chroni się przed tym od dawna, bo już od wersji 85, a z przeglądarek bazujących na Chromium - Brave również jest odporny.
Istnieją wtyczki, które pozwalają na blokowanie niektórych aspektów Fingerprintingu - np. nie pozwalają stronom rysować po canvas bez naszej zgody. Niestety próby utrudniania przez nas fingerprintingu mogą czasem sprawiać, że nasz fingerprint jest bardziej unikalny...
Na tych stronach możesz sprawdzić skuteczność fingerprintingu i przetestować wybrane przez siebie metody obrony przed nim:

https://www.bitestring.com/posts/2023-03-19-web-fingerprinting-is-worse-than-I-thought.html
3. Federated Learning of Cohorts (FLoC)
Jest to nowa, póki co eksperymentalna, technologia od Google. Działa tak, że to przeglądarka generuje fingerprint Twojej historii przeglądania i następnie używa go do śledzenia Cię w Internecie. Dzięki temu Google jest w stanie brać w śledzeniu pod uwagę nawet te strony, które nie mają osadzonych na sobie żadnych skryptów od Google'a.
Co ciekawe, ta funkcja jest opt-out dla administratorów stron. To oznacza, że domyślnie wszystkie strony są brane pod uwagę, dopóki strona nie zostanie skonfigurowana tak, aby sygnalizować brak zgody na udział w tym procesie śledzenia. Jak się pewnie domyślacie, nasza strona jest skonfigurowana tak, aby nie brała udziału w FLoC.
FLoC jest włączony tylko dla małego procenta użytkowników Chrome 89+. Możesz sprawdzić, czy jesteś jednym z nich, za pomocą strony amifloced.org.

4. Localhost tracking
Najnowszy i całkiem cwany sposób na śledzenie użytkowników. Wymaga, aby użytkownik miał zainstalowaną na swoim urządzeniu mobilnym aplikację (np. Facebook, Instagram). Aplikacja pozostaje włączona w tle, nawet gdy użytkownik z niej aktualnie nie korzysta. Umożliwia to komunikowanie się pomiędzy aplikacją a skryptami śledzącymi na stronach, które użytkownik odwiedza w przeglądarce. Dzięki temu skrypty śledzące mogą wiedzieć, który użytkownik aktualnie odwiedza ich stronę - nawet, jeżeli nie ma żadnych cookiesów Facebooka w przeglądarce.

Jakie technologie są używane do transmisji naszych danych?
Cookies
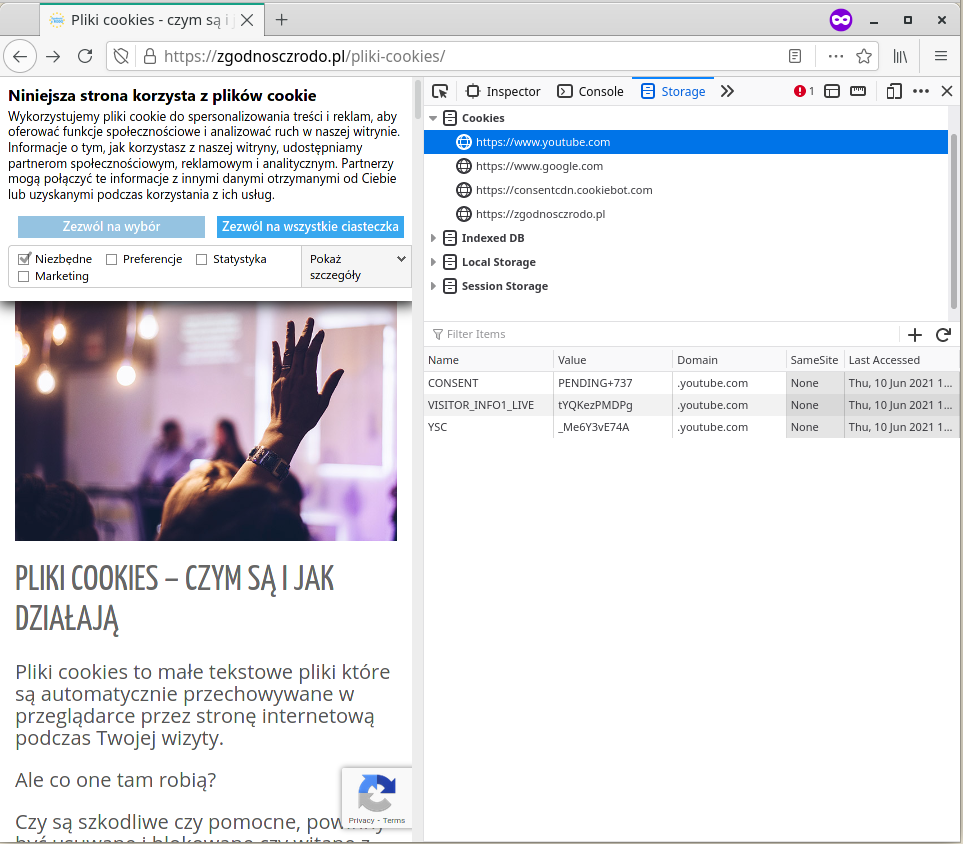
Cookiesy to małe bloki danych, w których strona może zapisywać dowolne informacje tekstowe. Te dane następnie będą wysyłane przez przeglądarkę za każdym razem, gdy ta będzie pobierała coś z tej samej strony. Dzięki temu możemy np. zalogować się do strony raz i nie musieć podawać hasła przy każdym jej odświeżeniu - gdyż strona zapisze sobie w cookies sekretny identyfikator, który zostanie przez nią rozpoznany przy następnych odwiedzinach.
Przeglądarka nie pozwala wprost czytać treści cookiesów ustawionych przez jedną stronę żadnej innej stronie, ale przy odrobinie współpracy dwie strony nadal są w stanie wymieniać się danymi z cookies. Cookies jest dobrym miejscem do przechowywania losowo wygenerowanego ID użytkownika przez skrypty śledzące - wystarczy je ustawić raz, aby przeglądarka posłusznie opatrywała nim wszystkie zapytania dotyczące danej strony.
Cookies można wyczyścić za pomocą ustawień przeglądarki. Można też sprawdzić ich treść w inspektorze danych w narzędziach deweloperskich:
LocalStorage
LocalStorage jest bardzo podobne do Cookies. Też pozwala na zapisywanie danych, które przeglądarka próbuje izolować dla każdej strony z osobna, i też mamy w nie wgląd za pomocą narzędzi deweloperskich. Są za to dwie główne różnice:
- Nie można pisać i czytać z LocalStorage przy wyłączonym JavaScript w przeglądarce;
- Dane z LocalStorage nie są automatycznie wysyłane przez przeglądarkę do każdego zapytania dotyczącego danej strony. Dane te muszą być dopisane przez skrypt JavaScriptowy.
Parametry URL
Metoda pozwalająca śledzić nie tylko konkretnego użytkownika, ale także osoby, z którymi się komunikuje. Facebook używa jej notorycznie. Gdy odwiedzamy jakąś stronę z facebooka, Facebook dokleja do jej adresu unikalny dla danego użytkownika i linka identyfikator. Przykładowo link:
https://www.internet-czas-dzialac.pl/odcinek-19-ekrany-przyciagajace-uwage/Zmienia się w:
https://www.internet-czas-dzialac.pl/odcinek-19-ekrany-przyciagajace-uwage/?fbclid=IwAR2PGXQYhvllPkX7E8H9Q1zjWChvmGbaAqthIu6xTb7hxSvti5C75SWUDodanie parametru fbclid nie zmienia tego, dokąd prowadzi ten link. Jednak ten atrybut pozostaje w pasku adresu i gdy użytkownik wysyła komuś linka z tym parametrem, to:
- ujawnia innym użytkownikom, że ma ten link z Facebooka lub od kogoś, kto znalazł go na Facebooku;
- daje Facebookowi szansę na śledzenie tego, kto komu udostępnia ten link - nawet poza facebookiem.
Warto nadmienić, że akurat nasza strona jest tak skonstruowana, że gdy napotka parametr fbclid, to usuwa go z paska adresu - spróbujcie sami: https://www.internet-czas-dzialac.pl/odcinek-19-ekrany-przyciagajace-uwage/?fbclid=IwAR2PGXk6xTb7hxSvti5C75SWU 😉
Parametry w linku, możemy również wykorzystać do zawarcia adresu do innej strony. Kiedy klikamy w reklamy lub niektóre okazje np. na stronie Pepper, możemy zauważyć początek adresu rozpoczynający się np. od googleads.g.doubleclick.net, czy też clkde.tradedoubler.com oraz zawartą informację o docelowym linku:
https://clkde.tradedoubler.com/click?p(289664)a(2381265)g(24276568)epi(0k004nbpp8aw)url(https://www.empik.com/rebel-gra-pictomania-rebel,p1218994734,zabawki-p)po wejściu na powyższy adres, usługa zanim stojąca przekierowuje nas do rzeczywistego adresu (po drodze rejestrując pozostałe idki zawarte w linku):
https://www.empik.com/rebel-gra-pictomania-rebel,p1218994734,zabawki-pAdvertising ID na smartfonach
Android i iOS mają funkcjonalność generowania losowego ID, które jest używane w celu śledzenia aktywności konkretnego użytkownika w różnych aplikacjach. W ekosystemie Apple nazywa się to Identifier for Advertisers, a na Androidzie - Advertising ID. Dotychczas ta funkcja była domyślnie włączona, ale od iOS 14 użytkownik musi wyrazić jednoznaczną zgodę na jej włączenie i może bez problemu pozostawić ją wyłączoną. Google wprowadzi podobne zmiany w Androidzie w tym roku.
Te identyfikatory można zresetować, aby otrzymać „nową tożsamość” w oczach skryptów śledzących na urządzeniach mobilnych. W iOS robimy to w ustawieniach systemowych, na Androidzie robimy to w ustawieniach aplikacji Google. Warto to zrobić, jeżeli np. zainstalowaliście jakąś aplikację tylko po to, aby otrzymać zniżkę w sklepie i zaraz potem ją odinstalowaliście, myśląc, że to wystarczy aby właściciel aplikacji nas dalej nie śledził.
Mobilne przeglądarki internetowe nie mają dostępu do IDFA/Advertising ID, więc śledzenie w aplikacjach nie jest za ich pomocą łączone ze śledzeniem na stronach internetowych. Kto wie, może to jest jeden z powodów, z których tyle stron wciska (a czasami nawet wymusza) instalowania aplikacji mobilnych?
Nagłówek „Referer”
Gdy użytkownik odwiedzający witrynę A klika na niej link prowadzący do witryny B, często przeglądarka informuje witrynę B o tym, z jakiej witryny „przyszedł” użytkownik, za pomocą nagłówka Referer. Autorzy stron mogą kazać przeglądarce tego nie robić na ich stronie, a użytkownicy mogą wyłączyć to zachowanie całkowicie.
Przeglądarki wbudowane w aplikacje do social media
Facebook, Twitter, Instagram na urządzeniach mobilnych nie wypuszczają użytkowników z aplikacji, gdy ci klikną w linka do strony www. Otwierają tę stronę w tzw. WebView, do którego doklejają skrypty śledzące i mają możliwość śledzenia całego ruchu użytkownika na tej stronie – nawet, jeżeli autor strony nie umieścił na niej żadnych skryptów śledzących.


Jak się chronić przed takim śledzeniem?
Wzmocniona ochrona przed śledzeniem w Firefoxie
Trudno jest polecić prostą metodę na ochronę przed opisanymi w tym artykule metodami śledzenia. Na pewno warto rozważyć korzystanie z Firefoxa, który ma wbudowane (bardzo skuteczne!) zabezpieczenia przed najpopularniejszymi skryptami śledzącymi:
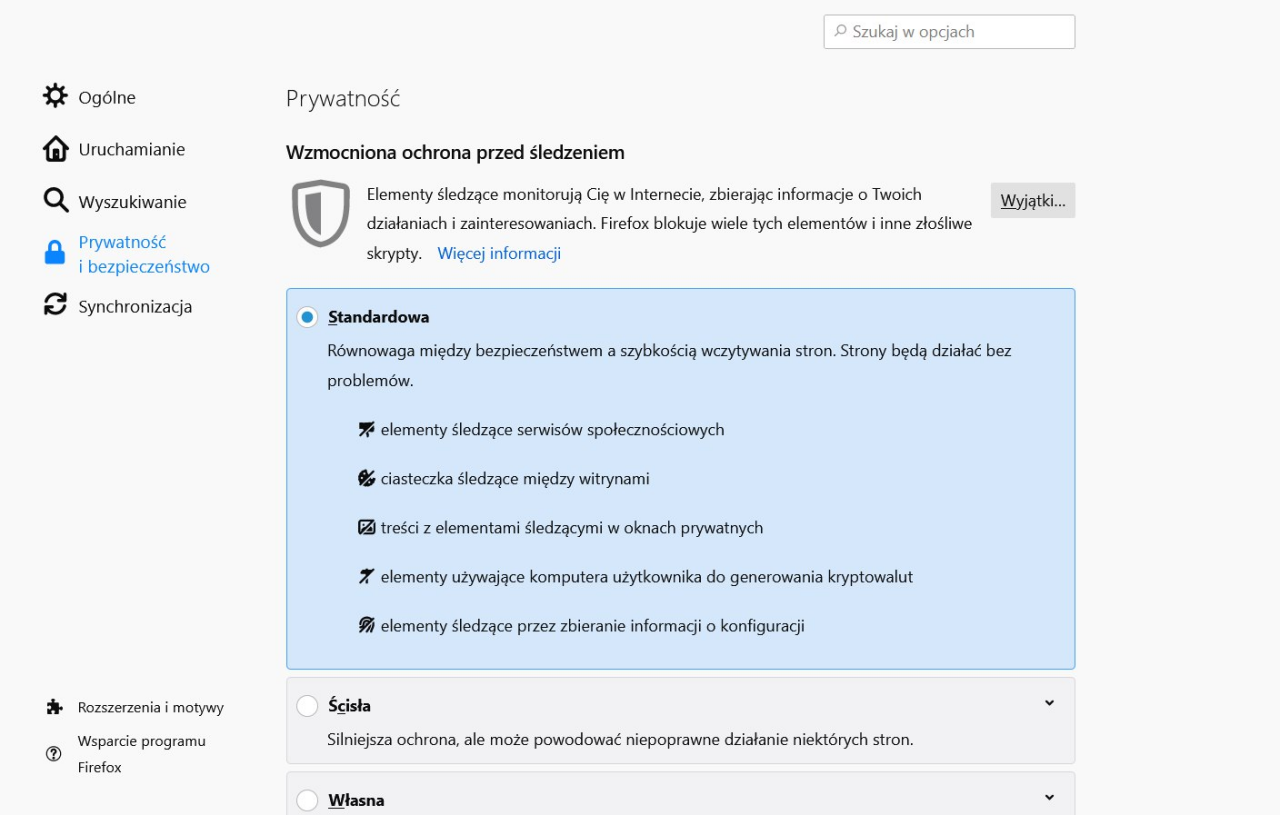
Już samo włączenie tych skryptów sprawia, że widać mniej reklam, a te które się pojawiają są znacznie mniej spersonalizowane.
Można też włączyć zaawansowaną ochronę przed fingerprintingiem w najnowszym Firefoksie:

Wtyczki do przeglądarek
Można wzmocnić swoją ochronę za pomocą dodatkowych wtyczek:
- Jeżeli nie chcemy zbyt wiele konfigurować - https://ublockorigin.com/
- Jeżeli chcemy mieć kontrolę nad absolutnie wszystkim - https://addons.mozilla.org/pl/firefox/addon/umatrix/
- Jeżeli chcemy czyścić linki ze wszelkiego rodzaju przekierowań i trackujących parametrów -
https://addons.mozilla.org/en-US/firefox/addon/clean-links-webext/ (wtyczka nie jest idealna - potrafi popsuć niektóre strony)
Inne wtyczki warte rozważenia:
- https://www.eff.org/https-everywhere
- https://privacybadger.org/
- https://decentraleyes.org/
- https://duckduckgo.com/app
- https://clearurls.xyz/
- https://addons.mozilla.org/en-US/firefox/addon/multi-account-containers/
- https://addons.mozilla.org/en-US/firefox/addon/facebook-container/
Pi-hole
Ponadto można skorzystać z oprogramowania Pi-hole, które tworzy czarną dziurę dla reklam i śmieciowych stron w Internecie. Blokowanie dzieje się na poziomu sieci domowej, dlatego jest to fantastyczne narzędzie zwłaszcza, gdy chcemy „zainstalować ad-blocka” na urządzeniach, które nie oferują takiej możliwości. Na pewno przygotujemy o tym dedykowany materiał!
Internet nie jest dobrym miejscem dla naszej prywatności. Mamy nadzieję, że wiedza z tego artykułu pomoże Wam korzystać z niego w bezpieczniejszy i bardziej świadomy sposób. Póki co korzystanie z Internetu i wystawianie się na ryzyko bycia śledzonym to przykry obowiązek nowoczesnego życia... Na szczęście zaczyna tworzyć się alternatywa.
Aktualizacja 30-11-2021: na horyzoncie pojawia się też możliwość śledzenia użytkowników za pomocą CSS.
Aktualizacja 2022-07-07: Firefox wdraża nowe zabezpieczenia przed śledzeniem: https://www.theregister.com/2022/06/30/firefox_tracking_cookie_loophole/
Aktualizacja 2023-04-23: Dodaliśmy informację o nagłówku Referer
Aktualizacja 2025-07-19: Dodanie Localhost Tracking do listy
Aktualizacja 2026-05-03: Dodanie opisu Supercookies (opis autorstwa Piotra Młynarskiego)
Źródła:
- https://browserleaks.com/
- https://amiunique.org/fp
- https://coveryourtracks.eff.org/
- https://palant.info/2020/12/10/how-anti-fingerprinting-extensions-tend-to-make-fingerprinting-easier/
- https://www.vox.com/recode/2020/6/22/21299398/apple-ios14-big-sur-privacy-wwdc-2020
- https://www.adexchanger.com/mobile/google-tightens-limit-ad-tracking-policies-for-android-ad-id/
- https://support.mozilla.org/pl/kb/jak-firefox-chroni-przed-fingerprintingiem
- https://krausefx.com/blog/ios-privacy-instagram-and-facebook-can-track-anything-you-do-on-any-website-in-their-in-app-browser
- https://krausefx.com/blog/announcing-inappbrowsercom-see-what-javascript-commands-get-executed-in-an-in-app-browser
- https://www.bitestring.com/posts/2023-03-19-web-fingerprinting-is-worse-than-I-thought.html
- https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Referer
- https://www.privacyinternational.org/guide-step/4148/change-http-referer-settings-firefox
Powiązane:
 Kuba Orlik
Kuba Orlik
 Nic Mulvaney
Nic Mulvaney
With Twitter's change in ownership last week, I'm probably in the clear to talk about the most unethical thing I was asked to build while working at Twitter. 🧵
~ Steve Krenzel @stevekrenzel
https://twitter.com/stevekrenzel/status/1589700721121058817